How Google (probably) Leverage Old TPUs for cheap LLM Inference
How Google (probably) Leverage Old TPUs for cheap LLM Inference
I was listening to the most recent Latent Space podcast with Marc Andreessen, the conversation riffs across the agentic software revolution, open source, why this is different to the dotcom bubble... however one line piqued my interest. In a discussion about inference economics and forward projections on cost, he says something like "my understanding is Google are running inference on very old TPUs, very profitably". To which the hosts agreed, though it was half caveated, without too much underlying evidence, but I went on to think about all the reasons that it's very likely true, and voila, a blog post is born.
What TPUs are and why they exist
Around 2013, Google's leadership and the Google Brain team ran a back-of-the-envelope calculation which went something like: "if every Android user uses our new voice search feature for just 3 minutes per day, we'd need to double our entire global data centre capacity to handle the load". CPUs / GPUs were the hardware of the time, and the maths didn't quite work to scale this out.
The response was to design a new type of chip from scratch, an application-specific integrated circuit (ASIC) tuned for the mat mul operations that sit at the heart of every neural network. This idea became the "Tensor Processing Unit" (TPU), which was first deployed internally at Google in 2015, announced in 2016, and documented in the 2017 ISCA paper that demonstrated 15-30x increased perf and 30-80x perf per watt compared to the CPUs and GPUs of the day (you can read the paper for more detail here). These TPUs now power search, youtube, maps, gmail etc., as well as Gemini, serving huge numbers of users all over the world.
To understand why these TPUs remain useful in a world where Nvidia are famously increasing the power of GPUs, let's take a high level look at the architecture and features. GPUs were originally designed for graphics and act as brilliant parallel processors, but they carry what we'll call "architectural baggage." Before the recent nvidia optimisations over the last few years, they spent significant energy and chip area on complex tasks like caching, branch prediction, and managing thousands of independent threads i.e. capabilities inherited from their graphics rendering origins. For AI inference specifically, much of that hardware was doing nothing useful. Transistors that handle rasterisation and texture mapping were idling while the chip was grinding through matrix multiplications.
The TPU's aim was to strip away baggage and commit more resource to the matrix multiplications. At it's core is a systolic array, which is a grid of multiply-accumulate units arranged so that data flows through them rhythmically (I guess like blood through a heart, hence systolic). For matrix-heavy workloads, data movement between off-chip memory and compute is a big bottleneck, and the TPU's systolic array addresses this with a fixed dataflow architecture. Once a tile of model weights is loaded into the array, it's reused across multiple inputs as activations flow through neighbouring processing elements, minimising redundant memory accesses for intermediate results. This is a more deterministic data movement which reduces control overhead compared to a GPU (at the time) cache based approach, though both architectures still fundamentally depend on streaming weights and activations from high-bandwidth memory.
A systolic array's fixed dataflow also removes a source of performance variability being there are no cache miss penalties or dynamic scheduling decisions at the compute level. This makes latency a little more predictable than on a GPU, where cache behaviour and warp scheduling introduce noise. But TPUs are not free of variability, interconnect contention across multi-chip pods, batching dynamics, and thermal throttling all still affect tail latency. For fleet-scale routing across hardware generations though, the narrower latency distribution is an operational advantage.
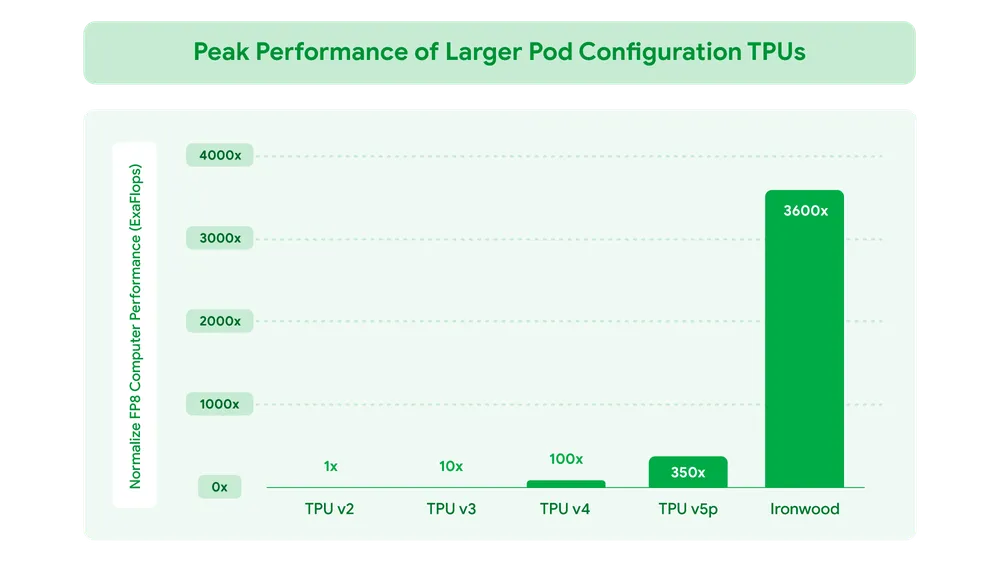
The original TPU v1 was a purpose-built 8-bit inference accelerator with a 256×256 systolic array. Then the next generations varied quite significantly, adding HBM, bfloat16 support, training capability, and inter-chip interconnects, making them fundamentally different machines rather than linear descendants. The consistency though is a bias toward high-throughput, low-precision matrix arithmetic, which aligns well with the industry's move toward quantised inference. The latest generation, Ironwood, extends this with native FP8 support, though there is now a broader industry trend toward sub-8-bit quantisation (4-bit, GPTQ, AWQ).
Heterogeneous Fleet Strategy
As new versions of TPUs have released, the prices of old ones have dropped dramatically. There's a quote from uncover alpha here stating that once v4 of the TPUs were released, v2s came down so low it was practically free to use compared to any Nvidia GPU. Google made good on a promise to keep older generations supported, whilst releasing more performant newer ones. Given this I would imagine the vast majority of internal workloads at Google are TPU-powered.
So you then end up with a tiered fleet, with some cutting edge chips like Trillium (v6e) and Ironwood (v7) likely supporting the hardest, most latency sensitive workloads. Then older generation chips absorbing the enormous volume of routine inference requests at dramatically lower cost. The spec gaps between generations are large with Ironwood delivering 4,614 TFLOPS of FP8 compute per chip. v5p sits at around 459 TFLOPS of BF16, though admittedly these are different precisions, so the raw numbers aren't directly comparable. In memory, Ironwood offers 192 GB of HBM3e per chip at 7.37 TB/s bandwidth, versus v5p's 95 GB of HBM2e at 2.77 TB/s. The spread is what makes the economics work, i.e not every query needs the latest generation's bandwidth and capacity.
The cost structure for production likely compounds this advantage, Google designs its TPUs and has Broadcom fabricate them, avoiding Nvidia's full-stack margin on GPUs, CPUs, switches, NICs, cabling, and connectors. SemiAnalysis estimates this all results in the TCO per Ironwood chip being 44% lower than the TCO of an Nvidia GB200 server, though this is from their own cost modelling and isn't necessarily publicly verifiable. You start to see, though, how this cost cascades to older, depleted generations of hardware.
XLA & JAX
Before getting into specific inference techniques, it's worth touching upon XLA (accelerated linear algebra) and JAX. XLA is Google's domain specific compiler for machine learning and JAX is the python framework built on top of it. The two of them form an abstraction layer that lets a single model definition compile to machine code across every generation of TPU without rewriting any model code.
When a function is JIT-compiled with JAX, the ops are traced into an intermediate representation (IR) called HLO (high level opcodes). XLA then performs optimisations, e.g. op fusion, memory layout optimisation, parallelisation, before compiling to hardware specific machine code. For TPUs, this compiles into VLIW (Very Long Instruction Word) packets sent directly to the hardware. The compiled graphs are cached, so repeated operations reuse the optimised binary.
The compiler first design differs from the GPU ecosystem, which is more of a kernel-based approach. Performance has historically depended on more hand optimised libraries like cuDNN and TensortRT. Google's internal docs make the case that the compiler centric approach "creates a durable advantage in a rapidly evolving research landscape," because new research architectures can be compiled without waiting for hand-written kernels. This is a structural difference to GPUs but they have been closing the gap, PyTorch's torch.compile with Triton are tools like CUTLASS are moving GPU development towards a more compiler driven model. It's the maturity and integration that are the key differentials though, XLA has been the primary performance path for TPUs from the start, where the GPU ecosystem's compiler tooling is newer and more fragmented.
I think the main point I'm trying to make here is that a longer history of consistent focus on aligning software to the hardware it runs on, has very likely made it much easier for Google to keep many of it's older version TPUs up to modern standard for LLM inference. Google can write a model once in JAX, compile it with XLA, and deploy it across v4, v5, v6, and v7 hardware. XLA handles per-generation code generation automatically. This doesn't mean every generation runs at equivalent efficiency out of the box, as sharding strategies, batch sizes, and memory layouts often need per-generation tuning, and then architectural shifts like Ironwood's move from MegaCore to a dual-chiplet model change how devices are exposed to JAX. The portability works though - the model code doesn't need to be rewritten.
Quantisation
No discussion around TPUs is complete without discussing quantisation - reducing model weights from BF16 precision down to INT8 or INT4, roughly halves or quarters the mem bandwidth required per inference. The original TPU v1 was an 8-bit mat mul engine, with the hardware specifically designed for low-precision compute. While subsequent generations added BF16 (a format Google Brain invented specifically for neural networks) and Ironwood introduced native FP8, the architecture has always been optimised for high-volume, low-precision operations. A quantised model fits more comfortably on older hardware and runs faster, though at the cost of some precision that, for the vast majority of queries, doesn't necessarily matter.
Intelligent Model Routing
Model routing has been an avenue of research from the frontier labs of late, and it's easy to see why, if you run everything on your best chips you waste money. Someone asking "why can't may friend see my localhost" doesn't need to be answered by Opus 4.6. On the other hand, if you run everything on your cheapest chips, you accept degraded quality. In an ideal world you match each request to the cheapest hardware that can service it to your required quality standard.
The idea has been formalised in open research. RouteLLM (Ong et al., 2024), from the Berkeley LMSYS group behind Chatbot Arena, demonstrated a framework for dynamically selecting between a strong and weak model at inference time. Their routers achieved cost reductions of over 85% on MT Bench and 45% on MMLU compared to always routing to GPT-4, while maintaining 95% of its performance. The router is lightweight (trained on human preference data), and the transfer learning generalises even when you swap the underlying models. Most importantly though, routing doesn't require calling both models with the router classifying a query upfront and routing to a single model.
More recent work pushes the routing approach further to include cascading. Dekoninck et al. (2024), accepted at ICML 2025, proposed cascade routing that can route to any model initially and re-route if confidence is low, with a formal proof of optimality for the combined strategy. It becomes easier to see how these techniques might be used at a frontier lab with an enormous amount of hardware to optimise.
Then we move onto something I discussed in my earlier blog post
Prefill / decode disaggregation i.e. an approach to hardware-level routing
There's a deeper form of routing that operates within a single inference request. LLM inference has two distinct phases, prefill (processing the input prompt in parallel, compute bound) and decode (generating tokens one at a time - memory-bandwidth-bound). DistServe (Zhong et al., OSDI 2024) demonstrated that running these phases on separate hardware pools can serve 7.4x more requests or meet 12.6x tighter latency targets on the same hardware budget. By mid-2025, Meta, LinkedIn, Mistral, and Hugging Face were all running disaggregated vLLM in production. Nvidia also built their Dynamo inference framework around this pattern.
For my old-TPU = cheaper inference hypothesis, this is the most directly relevant technique. You can imagine a fleet topology where prefill and decode run on separate hardware pools, and you assign compute-heavy prefill to newer chips with massive HBM bandwidth, while memory-bandwidth-bound decode runs on the cheap fleet (where the older TPUs live). Combined with model-level routing, you get two layers of hardware tiering where the router selects which model to use, and disaggregation selects which hardware pool handles each phase. A single user request might touch multiple hardware generations and the end user would never know the difference.
Conclusion
To conclude it's worth a mention on Anthropic's purchasing of TPUs, last year (2025) they committed to up to one million TPUs worth tens of billions of dollars and expected to bring well over a gigawatt of capacity online in 2026. Then about 2 days ago, we got details on a futher TPU expansion for multiple gigawatts of compute to come online in 2027. There must be something about the price : performance on these TPUs!
TL;DR:
- The compounding effect of Google's TPU / custom silicon investment, across hardware, compiler tooling, and fleet management, is not something you can easily replicate by buying Nvidia GPUs and standing up a Kubernetes cluster.
- Old TPUs probably don't retire, they depreciate. Once the accounting cost hits zero, the marginal cost of inference is power and cooling.
- XLA and JAX make cross-generation deployment viable. Model code doesn't need rewriting, even if deployment configs do.
- Model routing means most queries never need the best hardware. If a lightweight router can handle 85% of traffic with a smaller model on a v4, Ironwood chips are free to do the work that actually requires their power.
- Prefill/decode disaggregation lets a single request span hardware tiers. Older chips handle the memory-bound decode phase, newer chips handle compute-heavy prefill.
- Anthropic's TPU commitments show their relevance, You don't sign up for 3.5 gigawatts of capacity on hardware you're not seeing strong unit economics from.
Sources:
- Marc Andreessen introspects on The Death of the Browser, Pi + OpenClaw, and Why "This Time Is Different" (Latent Space, April 2026)
- RouteLLM: Learning to Route LLMs with Preference Data (Ong et al., ICLR 2025)
- DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving (Zhong et al., OSDI 2024)
- Disaggregated Prefill and Decode (Perplexity AI Engineering Blog, 2025)
- Cache-aware prefill-decode disaggregation (CPD) for up to 40% faster long-context LLM serving (Together AI, 2026)
- Speculative cascades: A hybrid approach for smarter, faster LLM inference (Google Research, 2025)
- A Unified Approach to Routing and Cascading for LLMs (Dekoninck et al., ICML 2025)
- Cloud TPU documentation (Google Cloud)
- TPUv7: Google Takes a Swing at the King (SemiAnalysis, 2025)
- The chip made for the AI inference era (Uncover Alpha, 2025)
- Gemini 3 Pro Model Card (Google DeepMind, 2025)
- vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU (vLLM Blog, 2025)
- Building production AI on Google Cloud TPUs with JAX (Google Developers Blog, 2025)
- MaxText: A simple, performant and scalable Jax LLM (GitHub)
- Google TPU Architecture: 7 Generations Explained (Introl, 2025)
- Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell? (XPU.pub, 2025)
- Expanding our use of Google Cloud TPUs and Services (Anthropic, October 2025)
- Expanding our partnership with Google and Broadcom for multiple gigawatts of next-generation compute (Anthropic, April 2026)