LLM Inference Routing & Optimisation: Part 1 - Prefill & Decoding Disaggregation
LLM Inference Routing & Optimisation: Part 1 - Prefill & Decoding Disaggregation
LLM inference is a huge area of research currently as the frontier AI Labs scale up their reach to consumers. In my opinion this area of engineering is one of the most exciting areas in support of the global push for AI currently, as there is a significant amount of low hanging fruit to be obtained and squeezed out of existing hardware through the software, algorithmic innovations and architecture of the systems that run on top of it. Chris Fegly recently released a great book titled "AI Systems Performance Engineering", which I've been slowly working my way through. I wanted to write a series of posts, specifically on inference optimisations, to consolidate my own thoughts on the current state of research, my own experience in this space, and where the industry might go next. We'll start with a very important inference breakthrough:
Disaggregated Prefill and Decode
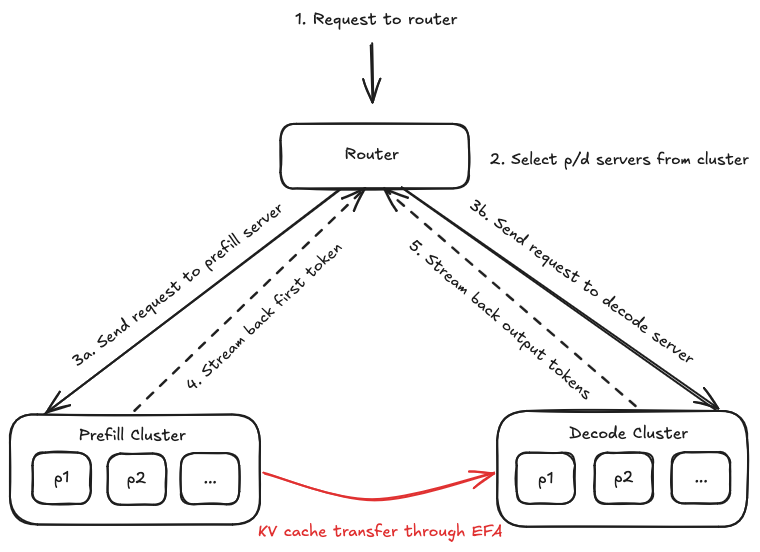
The inference flow for modern LLMs consists of two different phases, prefill and decode. Disaggregating prefill and decode means we can separate these stages, with the advantage being that we can scale each stage independently to significantly improve performance.
The prefill stage processes the entire input prompt in parallel, populating the KV cache for attention. It's compute-bound, as you're doing a massive matrix multiplication across all your input tokens at once. This is where your metrics of time-to-first-token (TTFT) comes from.
Decode generates output tokens one at a time, each dependent on the previous. It's memory-bandwidth bound, i.e. the GPU spends most of its time loading model weights from the high-bandwidth memory (HBM), not doing maths. This is where the inter-token latency (ITL) and the overall streaming experience comes from.
When framed as these two separate stages, the problem is obvious, if you run these two phases together on the same hardware, they interfere with each other. When using continuous batching (the standard for high throughput serving), new requests arrive while existing requests are mid-decode. So every time the GPU pauses decode to handle a prefill, your decode latency spikes, and you'll see a stutter in the token stream.
 - AWS Neuron - Disaggregated Inference
- AWS Neuron - Disaggregated Inference
This is known as the tail latency problem, and while your P50 ITL might look fine, your P95 / P99 are dominated by the prefill intereference. This problem is only amplified at longer and longer prompt lengths.
Running prefill and decode on the same nodes forces a single scheduling and resource allocation strategy for these phases, which have very different characteristics. Prefill having large parallel computations, and decode requiring many small sequential computations. Disaggregating prefill and decode assigns each phase to a different GPU pool, eliminating direct interference between the two workloads.
DistServe was the paper that proposed this separation on different hardware. If we remove cross phase interference, we massively reduce resource dead time where decoding tasks are stalling behind long prefill operations. GPUs therefore spend more time doing useful things and less time idling. This idea is to scale two clusters of GPUs by dedicating one set of nodes to handle prefill and another to handle the decode. The two clusters communicate only when transferring the encoded prompt state or the KV cache for attention. DistServe reported up to 7.4x more goodput (useful throughput at a given latency target) served within both TTFT and Time per output token (TPOT) constraints.
So a bit more detail on the infrastructure side of how we might independently scale these clusters. As we mentioned previously decode stage uses smaller sequential computations, therefore we can run at much lower batch sizes, or with specialised scheduling, so we can minimise TPOT for streaming generation. You could, for example, use a specialised scheduler that prioritises urgent decode tasks to avoid any queuing delays. Prefill is heavier in it's computation, and is therefore optimised for low latency and improving TTFT.
As mentioned, in separating phases in this way, we need to transfer the KV cache from the prefill cluster to the decode cluster. In practice this actually incurs minimal additional latency because the communication uses high-bandwidth interconnects for multi-GPU and multinode transfers, NVLink, Infiniband, NVSwitch and Ethernet using GPUDirect RDMA.
Example Disaggregated Prefill and Decode on Kubernetes
Use of Kubernetes for disaggregated prefill and decoding can be a very useful thing, as we can either dynamically shift out the GPU pool allocations, or scale the pools out separately based on load and input characteristics. A concrete example - many users arrive with very long prompts and small outputs, a typical document summarisation usecase. K8s can shift allocation to use more GPUs in the prefill pool, on a temporary basis. The opposite is also true, if we have very long output requests, we shift more resource to the decode pool.
The open source llm-d aims to accelerate distributed inference by integrating industry-standard open technologies:
- vLLM as the default model server and engine
- Kubernetes Inference Gateway for use as a control plane API and load balancing
- Kubernetes as the actual infrastructure orchestrator and workload control plane
 vLLM implements disaggregated prefilling by introducing two instances of and handing off KV using LMCache and NIXL vLLM Disaggregated Prefilling, llm-d then extends this with kubernetes native orchestration for the disaggregated serving and KV-aware routing.
vLLM implements disaggregated prefilling by introducing two instances of and handing off KV using LMCache and NIXL vLLM Disaggregated Prefilling, llm-d then extends this with kubernetes native orchestration for the disaggregated serving and KV-aware routing.
Worth mentioning is the Variant Autoscaler component of this system, which is responsible for providing dynamic autoscaling capabilities for llm-d inference deployments, automatically adjusting replica counts based on inference server saturation. The autoscaler will optimise resource utilisation by adjusting to traffic patterns, and will make scaling decisions to reduce tail latency which are saturation based, i.e. the tradeoffs we discussed before with our examples of long inputs / short outputs or vice versa. Production systems at frontier labs likely use some variant of this system to scale their infrastructure up or down.
Research Avenues
Some promising avenues of research are emerging to even further improve efficiency gains for the technique of prefill / decode disaggregation. Several are described below:
CXL-Based Memory Disaggregation
As we've mentioned, the biggest bottleneck in current prefill / deoding disaggregation is KV cache transfer over the network. Even with RDMA, you're paying tens to hundreds of milliseconds to move gigabytes of cache state. CXL (Compute Express Link) is emerging as a potentially strong alternative.
TraCT proposes tightly coupling KV transfer and prefix-aware caching over CXL shared memory, enabling prefill and decode workers across a rack to communicate through a unified memory pool rather than through network transfers arXiv paper. It reduces average TTFT by up to 9.8x, lowers P99 latency by up to 6.2x, and improves peak throughput by up to 1.6x compared to RDMA and DRAM-based caching baselines, according to the research arXiv.
The key engineering insight here is that CXL shared memory provides lower and more stable prefill latency with improved sustainable throughput, than RDMA for KV transfer, even without the caching benefits. So this eliminates a network hop that dominates the existing prefill / decode pipeline latencies.
Hierarchical KV Cache
Rather than treating KV cache as an ephemeral artefact that lives and dies on a single GPU, one emerging approach is to treat it as a first-class data structure with a tiered storage hierarchy, very similar to how operating systems manage virtual memory.
LMCache transforms LLM engines from isolated token processors into a distributed ecosystem of compute and storage, where KV cache can be extracted, stored in a hierarchy of storage devices (GPU memory, CPU memory, local disk, remote disk, and Redis), and transferred across engines and queries - arXiv paper. The system uses dynamic offloading with reference counting to minimise data duplication across concurrent writes to multiple storage tiers.
llm-d 0 shipped hierarchical KV offloading as a headline feature - llm-d, with their architecture supporting a pluggable KV cache hierarchy including offloading KVs to host memory, remote storage, and systems like LMCache, Mooncake, and KVBM.
Dynamic Load Balancing and Weight Migration
A pain point in disaggregated serving is that cache-aware routing (i.e. sending requests to workers that already have relevant cache) conflicts with load-aware routing (sending requests to the least-loaded worker). Cache-aware routing creates hotspots and load-aware routing wastes cached context. I'll hopefully touch upon this in future posts.
BanaServe proposes solving this with three mechanisms -
- layer-level weight migration for coarse-grained redistribution of computation
- attention-level KV cache migration for fine-grained memory load balancing
- a Global KV Cache Store with layer-wise overlapped transmission to decouple routing decisions from cache placement Wiley Online Library.
The key idea is that if the cache can migrate to wherever the load balancer wants to send requests, you don't have to choose between cache affinity and load balance, you get both. This points toward a future where disaggregated serving systems aren't just static prefill / decode pools but dynamic, continuously rebalancing systems that migrate both compute and data in response to shifting traffic patterns.
Conclusion
To conclude our post then:
- Prefill and decode disaggregation has been a significant improvement in system design for LLM inference systems - by separating two fundamentally different workloads onto independent hardware pools, we eliminate cross-phase interference and unlock independent scaling, showing large gains in both TTFT and tail latency.
- Kubernetes-native orchestration (e.g. llm-d) makes disaggregation operationally viable at scale - dynamic autoscaling based on saturation and traffic shape (long inputs vs. long outputs) is how production systems translate the theoretical benefits of disaggregation into real infrastructure efficiency.
- KV cache transfer is likely the critical bottleneck to solve next, at least this is where research is trending - whether through CXL-based shared memory (TraCT), hierarchical tiered storage (LMCache), or dynamic cache migration (BanaServe), the emerging research consensus is that KV cache should be treated as a first-class, portable data structure rather than an ephemeral GPU-local artefact.
- The trajectory points toward fully fluid inference clusters - rather than static prefill and decode pools, future systems will continuously rebalance compute and cached state in response to live traffic, dissolving the hard boundary between routing, scheduling, and memory management.
- In Part 2 we will discuss modern parallelism strategies for serving large Mixture of Expert (MoE) models, including tensor, pipeline, expert, data and context parallel pipelines.
Sources:
- DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving (Zhong et al., OSDI 2024)
- TraCT: Disaggregated LLM Serving with CXL Shared Memory KV Cache at Rack-Scale (arXiv, 2025)
- LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference (arXiv, 2025)
- BanaServe: Balancing Disaggregated LLM Serving with Dynamic Weight and KV Cache Migration (Wiley Online Library, 2025)
- llm-d: Distributed LLM Inference on Kubernetes (GitHub)
- llm-d Architecture (llm-d Docs)
- vLLM Disaggregated Prefilling (vLLM Docs)
- AWS Neuron - Disaggregated Inference (AWS Docs)