LLM Inference Optimisation - Continuous Batching and vLLM
— 5 min read
LLM inference optimisation is a hot topic of discussion in the industry currently. LLMs have very high GPU memory footprint and enormous compute costs, so serving ends up being a significant issue for a lot of LLM based applications. Several optimisation techniques are available to improve efficiency of inference, and I want to talk about one known as "Continuous Batching" in this post, as well as how this is implemented in the fantastic open source tool vLLM.
A quick intro to LLM inference and Optimisation
This is a huge topic itself, so if you want more detail Hugging face have some great articles that go into more depth e.g. GPU Inference and LLM inference optimisation. For the purposes of this short blog post, I'll just give an overview.
In a nutshell, for each inference request to an LLM we:
- pass in a sequence of tokens (a prompt)
- In the decoder architecture, the LLM responds by iteratively producing a sequence of tokens autoregressive-ly based on the prior tokens in the sequence
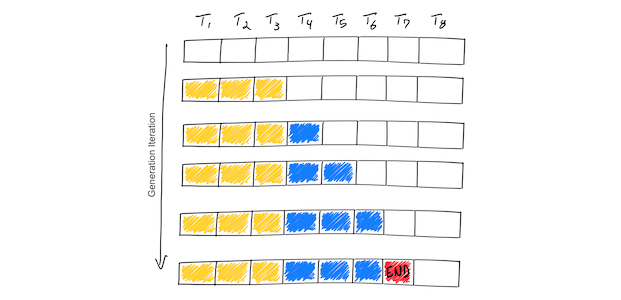
The simple diagram above demonstrates in blue the iterative generation of tokens until a end-of-sequence token (in red) is generated.
Optimisation Techniques
There are several model-based optimisations for LLM model inference that you may have heard of, quantisation is a key one, where we can reduce the memory usage by moving from 16-bit to 8-bit representations, allowing for doubling the space available for batch sizes. However, given that LLM inference is memory IO bound and not compute bound, inference throughput is largely subject to how large the batch is that you can fit into your GPU memory. A good example is that it takes more time to load 1MB of data to the GPU's compute cores, than it does for those compute cores to perform the LLM computations on that 1MB of data.
Though GPUs have an enormous amount of available compute, LLMs struggle to achieve memory saturation because much of the memory bandwidth is spent actually loading the model parameters. We can use batching to improve this, i.e. instead of loading new parameters for every input sequence, we just load the model parameters once and then use them to process a batch of input sequences. This approach is called static batching, as the size of each batch remains constant until the inference is complete. There's a great image of this in action taken from AnyScale's blog .
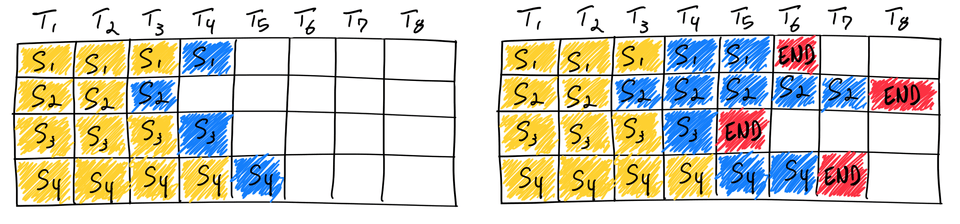
For a given batch, on the left we see 4 sequences generating their next token. On the right, after several iterations, we see the stop token (in red) generated after varying numbers of iterations for each sequence. This shows us that with static batching, the GPU will be underutilised until we finish all the sequences in the batch, therefore the throughput for inference is determined by the longest sequence (i.e. the second one down).
So how can we improve this?
Continuous Batching
In 2022 a paper was released that introduced a distributed serving system for transformer based generative models. This introduced the concept of iteration level scheduling, meaning that once a given sequence (i.e. one of the rows in the diagram above) has completed, a new one can be scheduled directly after it on the GPU without having to wait for any longer sequences to complete, this cranks up the GPU utilisation and reduces throughput time. There is a shortcoming here however, the prefill and generation phases have different computational requirements, e.g. prefill may well have more intensive computation over the initial input, while generation might be lighter per token but needs to be done iteratively. This means that both these phases can't easily be batched together for processing on the GPU. Typically this is managed with the tuning of a hyperparameter waiting_served_ratio, which determines the ratio of requests waiting for prefill, to those in the generation phase.
- If we have a high
waiting_served_ratio: the system prioritises processing initial inputs (prefill phase) more than generating new tokens (generation phase). This might be useful if many new requests are coming in rapidly. - With a low
waiting_served_ratiothe system prioritises generating new tokens over processing new inputs. This could be useful if most requests are already in the generation phase and waiting for their responses.
vLLM
vLLM is an open source tool and advanced optimisation framework designed to enhance the efficiency of LLM inference. It builds on the basic implementation of continuous batching by implementing dynamic batching, which adjusts batch sizes in real time based on load, and token-level batching, which groups tokens from different requests together for more efficient processing. But how does it do this?
PagedAttention allows the KV cache to be non-contiguous by pre-allocating cache sizes, allowing it to be non-contiguous in memory. The attention mechanism then works on block-aligned inputs, allowing the computation of the Keys and Values per token to be operate on these non-contiguous memory ranges. What this means in practice is that we enable Just-In-Time (JIT) allocation of buffers rather than Ahead-of-Time (AOT), so for a new generation, we don't need to allocate a contiguous buffer of the maximum context length. The schedule can decide on every iteration if it needs more room for a particular generation. This significantly reduces memory wastage from the AOT allocation schemes used before. It isn't perfect, but their blog reports a reduction of memory wastage to under 4%.
As a result of implementing PagedAttention we allow the system to batch more sequences together and therefore increase GPU utilisation significantly, which therefore significantly increases the rate of throughput when serving LLM models.
Conclusion
This post has been a short exploration into what makes LLMs memory hungry in production, and explains some of the approaches to reduce that overhead. This sort of post helps me keep up with the latest in the industry, so I hope my summary helps you too. Personally I'm excited for the trends in LLM optimisation to continue, and I would particularly like to see small, highly effective models, running on smaller hardware (big dreams, I know).
Refs https://blog.vllm.ai/2023/06/20/vllm.html https://www.anyscale.com/blog/continuous-batching-llm-inference