Flyte's FlytePropeller and Go Worker Pools
— 10 min read
Flyte
I've recently been digging into Flyte as an orchestrator tool for MLOps workflows, which has gained significant adoption as an open source framework for executing complex ML workflows over the past couple of years. It offers a whole host of advantages for running modern MLOps workflows, for example:
- runs natively on kubernetes - much like kubeflow
- strong data typing between tasks in workflows - lack of this has stung me before
Much like ML models themselves, don't treat your open source tools like a black box. It helps to understand how they work under the hood, as when they inevitably bug out, you're going to be the one who has to fix it, and if you understand some of the lower level implementations, you're going to save yourself a whole lot of pain. So this post aims to do that with a particular component of Flyte. This is a dive specifically into the "FlytePropeller" architecture and implementation which supports Flyte's workflow orchestration.
FlytePropeller
The component in Flyte that grabbed my eye initially was the FlytePropeller, which is the workflow orchestrator component of the Flyte stack. This component is responsible for the scheduling and tracking of Flyte workflows, and is implemented through a kubernetes controller. K8s controllers typically follow the reconciler pattern, which in summary, watches a component's state and attempts to transition from the observed state to a requested state. If you've ever used terraform or ansible, you'll recognise the pattern. In Flyte, workflows are the resource, and FlytePropeller will evaluate the state of any workflows to transition from the current state to success. I won't go into the full details of the architecture in this post, but the full description of the architecture can be found here Below is a high level architecture diagram and flowchart of each component's responsibilities during a Flyte Workflow execution:
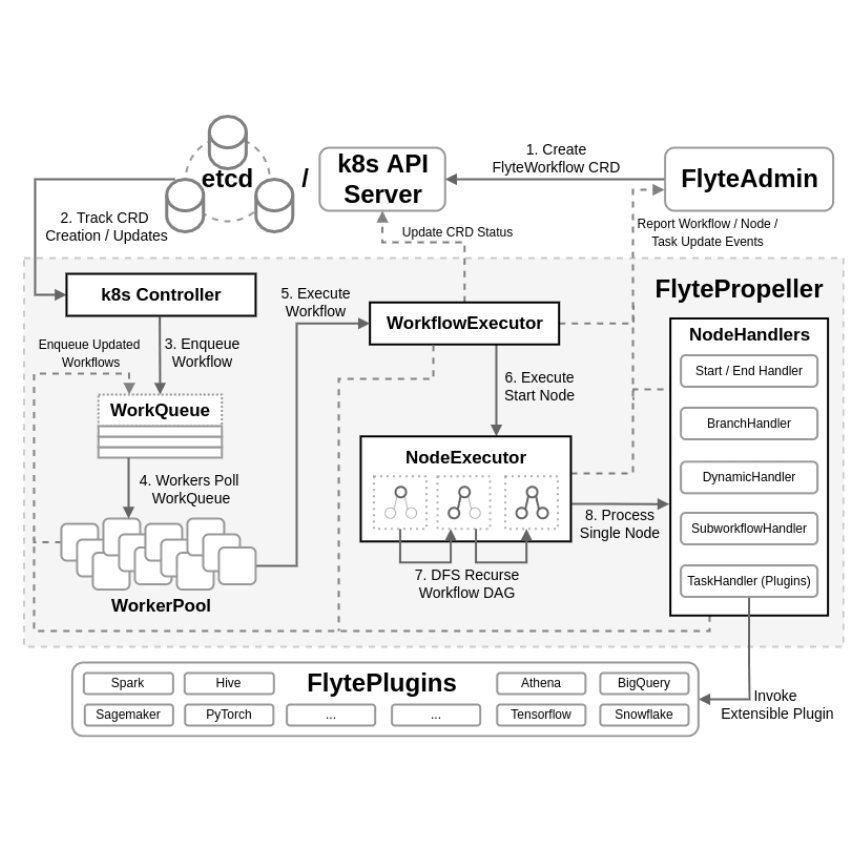
The focus for this post, is how the Flyte team has implemented its Controller, WorkQueue and WorkerPool components in FlytePropeller. Through utilising Go's lightweight "threads" goroutines, FlytePropeller's worker pool is able to scale to 1000s of workers on a single CPU. with each of the goroutines managed by the Go runtime. This is unique to Go's implementation, and makes it an excellent choice of language for workflow orchestrators.
One limitation / design consideration when working with Goroutines to design a workerpool, is ensuring that you limit the concurrency of tasks executed by the workers to the resources that you have available. This is where Flyte utilises kubernetes very powerful API to control the concurrency within the worker pool to the available resource.
Interestingly (but perhaps not unsurprisingly given the nature of open source software), this has been a topic of discussion previously. A popular open source worker pool implementation in Go is gammazero/workerpool which was inspired by a post from way back in 2015 - [Handling 1 million requests per minute with golang](- http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang) , and has demonstrated how we can leverage Goroutines to handler serious scaling of task execution with very low latency. I would thoroughly recommend reading through the repo and the blog post if you're interested in how these implementations have evolved. At the end of this post I play around with the gammazero implementation to read tasks from a Redis queue, a pattern which is useful for us in generating data at Ultraleap.
FlytePropellers WorkerPool
Diving into the code then, let's investigate how FlytePropeller's controller works:
/flytepropeller/pkg/controller/controller.go starts up the controller processor, i.e. the k8s Controller block in the high level diagram. The Controller object is represented as a struct and any dependencies are injected into the run function via this Controller struct. Let's break down the components at a high level. I've gone into a bit of detail on some of the more interesting components:
type Controller struct { workerPool *WorkerPool flyteworkflowSynced cache.InformerSynced workQueue CompositeWorkQueue gc *GarbageCollector numWorkers int workflowStore workflowstore.FlyteWorkflow // recorder is an event recorder for recording Event resources to the // Kubernetes API. recorder record.EventRecorder metrics *metrics leaderElector *leaderelection.LeaderElector levelMonitor *ResourceLevelMonitor executionStats *workflowstore.ExecutionStatsMonitor}- WorkerPool - this represents the pool of worker goroutines that process the workflow tasks concurrently. This is informed from a higher level in the Flyte stack on how much resource is available in the cluster to limit concurrency.
- flyteworkflowSynced - cache synchronisation function to indicate whether the FlyteWorkflow informer's cache has been synced.
cache.InformerSyncedtypically returns a boolean indiciating whether the cache is synced. K8s controllers often use informers to watch for changes in resources (remember our reconciler pattern?). Informers maintain a local cache of the state of these resources to reduce API server load. Therefore the FlytePropeller controller waits for workflows state to be synced in the cache before running, as we can see inworkers.go:
logger.Info(ctx, "Waiting for informer caches to sync")if ok := cache.WaitForCacheSync(ctx.Done(), synced...); !ok { return fmt.Errorf("failed to wait for caches to sync")}-
workQueue - a composite work queue that holds workflow items to be processed, a typical FIFO queue pattern.
-
gc - a custom garbage collector for cleaning up completed or old workflows
-
numWorkers - the number of worker goroutines to run
-
workflowStore - interface for interacting with stored FlyteWorkflows
-
recorder - an event recorder for logging kubernetes events related to the workflows
-
metrics - a struct for Prometheus metrics for monitoring the controller performance
-
leaderElector - used for leader election across multiple instance deployments to ensure only one instance is actively processing workflows. This is crucial in distributed systems where you want only one instance of a controller to be active at a time, this provides:
- high availability, with multiple instances of the controller being up for redundancy
- consistency - only one instance is "leading" i.e. making decisions, therefore we prevent conflicts
- resource efficiency - preventing duplicate work and resource contention
I could write a whole blog post on this topic itself (maybe I will...) but there are plenty of resources out there if you want to dig into leader election, specifically in kubernetes. But in a nut shell:
- instances of the controller try to acquire a lock on a specific resource, say a ConfigMap or Endpoint in k8s
- All instances try to create / update the local resource with their own identifier, but only one instance succeeds in acquiring the lease, and becomes the leader.
- The leader periodically renews its lease
- If the leader fails, you have redundancy and another instance acquires the lock and becomes the leader
This provides a high degree of fault tolerance. We aren't selecting the "best" instance here, we just want a pool of instances to give us high availability. It looks like Flyte is using the leaderelection package from k8s.io/client-go to handle the lower level implementation of leader election.
-
levelMonitor - reports on the current resource levels of the FlyteWorkflows per instance of the FlytePropeller.
-
executionStats - reporting and monitoring of any stats about workflow executions
So given the above implementations, we can breakdown the key components and flow of the controller:
- FlytePropeller's controller is initialised with the components from our Controller struct as discussed
- We optionally configure leader election if our config says so, as we discussed, only the leader actively processes workflows
- We then have our
Runmain loop, which:- initalises the worker pool
- starts the GC
- starts the resource and execution stats monitoring
- then waits for the informer cache to sync
- The worker pool runs a specified number of worker goroutines, where each worker picks up a workflow from the work queue, processes the workflow, and updates it's status. i.e. in
workers.gowe see:
// Launch workers to process FlyteWorkflow resources for i := 0; i < threadiness; i++ { w.metrics.FreeWorkers.Inc() logger.Infof(ctx, "Starting worker [%d]", i) workerLabel := fmt.Sprintf("worker-%v", i) go func() { workerCtx := contextutils.WithGoroutineLabel(ctx, workerLabel) pprof.SetGoroutineLabels(workerCtx) w.runWorker(workerCtx) }() }which is looping through the number of free workers (or goroutines, i.e. threadiness) in the worker pool, for them to then process work items from messages on the work queue:
// runWorker is a long-running function that will continually call the// processNextWorkItem function in order to read and process a message on the// workqueue.func (w *WorkerPool) runWorker(ctx context.Context) { logger.Infof(ctx, "Started Worker") defer logger.Infof(ctx, "Exiting Worker") for w.processNextWorkItem(ctx) { }}processNextWorkItem then processes a single item off the workqueue.
- As seen in the high level architecture diagram above, the worker then processes workflows for node updates on the node executor. This is done through calling the handler in the
processNextWorkItemfunction.
I hope this post has been useful in understanding how these sorts of orchestrators work, and how they can be used to process large amounts of tasks concurrently. I find exercises like this very useful for understanding my tooling, and it has the added side bonus of making it much easier for me to contribute to their open source code!
Go - Worker Pools
A quick Goroutines example
Go's excellently implemented Goroutines allow for the creation of large numbers of lightweight "threads" (nb - not actually threads in the CPU sense), to execute functions asynchronously. An example of a very basic goroutine (taken from Go by Example but edited slightly to actually force the async nature of goroutines to show when running...
package main
import ( "fmt" "time")
func f(from string) { for i := 0; i < 3; i++ { fmt.Println(from, ":", i) time.Sleep(100 * time.Millisecond) }}
func main() { f("blocking")
go f("goroutine")
go func(msg string) { fmt.Println(msg) }("going")
time.Sleep(time.Second) fmt.Println("Done")}And for the output we see the initial blocking function calls running first, followed by the 2 go routines running async:
❯ go run goroutines.godirect : 0direct : 1direct : 2goroutine : 0goinggoroutine : 1goroutine : 2doneThe next important concept in Goroutines are channels, which are pipes that connect concurrent goroutines. This makes it possible to send values into channels from one goroutine and receive them in another.
package main
import "fmt"
func main() {
messages := make(chan string)
go func() { messages <- "ping" }()
msg := <-messages fmt.Println(msg)}So back to our workerpool implementation in Go then. A popular implementation as I mentioned previously is the gamma zero workerpool , here's a quick description of it's implementation / some notes:
- the main Loop dispatch function - manages the entire pool of workers:
- checks for tasks in waiting queue (the failover queue if no workers are available), then processes them
- if the queue is empty, run task from the
taskQueuechannel
- Task processing, each task execution is in the context of a worker goroutine -
- if a worker is available, immediately send the task to be executed
- if all workers are busy, start a new worker (provided we haven't exceeded max worker limits)
- if all workers are busy and at max capacity, then add a task to the waiting queue
- Concurrency control:
- managed via system resource limits, but doesn't limit tasks, we limit by worker
- sync.WaitGroup is used to keep track of all active worker goroutines for graceful shutdown
- Shutdown process
StoporStopWait()are called for signalling the dispatch loop to exit
The reason for my investigation is it's potential use for us at Ultraleap. We generate simulated data by running a large number of concurrent tasks on our cluster, which gives us some of our input training data for our hand tracking models. Being able to scale tasks to our system resources is a very useful way of managing the control loop for generating data highly concurrently across multiple GPUs. As such I've implemented the following on top of the above worker pool implementation to better investigate how we might use it:
- run our Go program locally on a minikube cluster for testing and development
- implement a redis queue to read tasks for testing
You can find my implementation on my github along with setup instructions via the make file, feel free to test it out for your own usecase or learning!
I will be doing more exploration into Flyte, particularly for generative AI usecases, as I feel it will be a powerful tool for managing these complex and highly scalable MLOps systems.